如何导入每页包含一个条形码的PDF文档,获取条形码数据
原创 未经同意,请勿转载路径:标签生成器 - 《如何导入每页包含一个条形码的PDF文档,获取条形码数据》如果您有一个每页都包含一个条形码的PDF文档(例如以下PDF文档图示),希望把这些条形码的实际文本内容识别出来,并填充到【导入数据】的数据列表中。可以使用【导入PDF条形码数据】这个功能实现。

在【导入数据】模块中,点击【导入PDF条形码数据】按钮。

在弹出PDF文档导入页面中,点击【点击导入PDF文档】,本地选择需要识别条形码的PDF文档,程序即会自动读取PDF文档并识别其中的条形码。

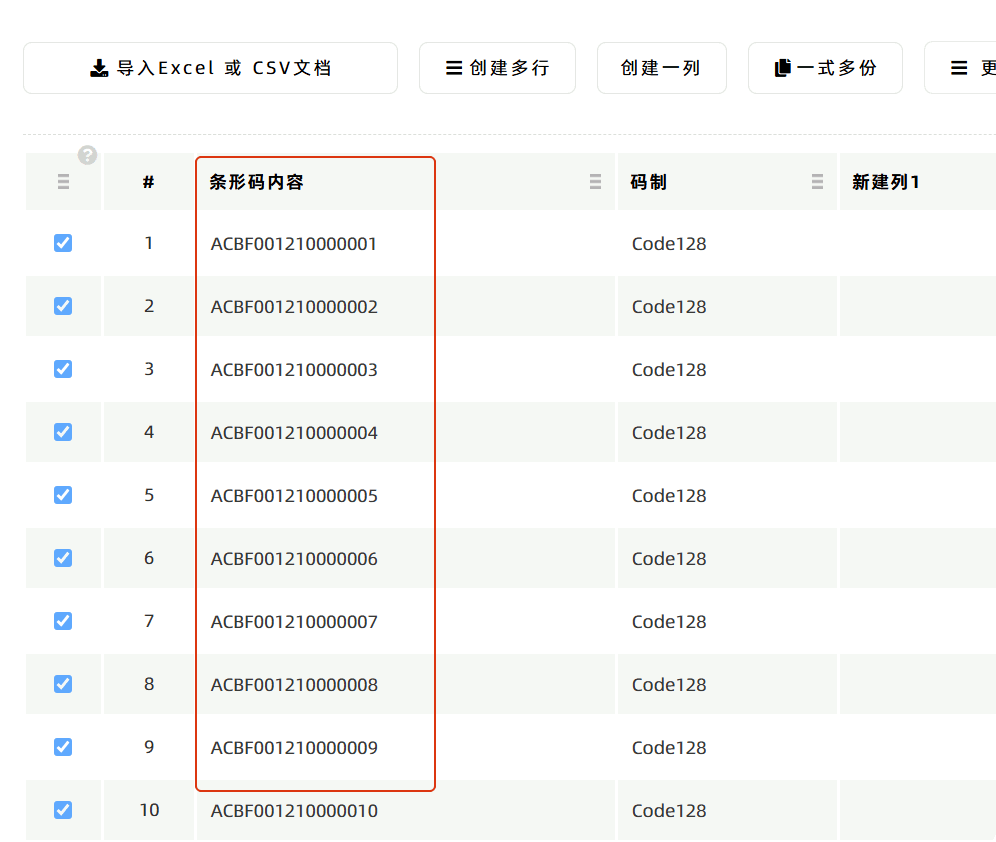
程序默认将识别到的条形码数据替换【导入数据】的数据列表,填充两列内容:条形码内容和码制。 如果希望保留原有的数据列表,可以勾选页面底部的【作为新的一列插入到数据列表中】选项,程序会将在原有的数据列表中插入条形码内容和码制两列内容。
如何将PDF文档中的条形码抠出来,插入到新制作的标签中?
具体操作步骤是,使用上面提到的【导入PDF条形码数据】功能,导入一页一码的PDF文档,程序会自动识别出条形码的文本内容,并将识别到的条形码文本内容填充到【导入数据】的数据列表中。 然后到【制作标签】中增加【条形码】组件,编辑【条形码】组件动态绑定到【导入数据】中数据列表的条形码数据,并且选择合适的码制,通常选用Code128(自动)。 至此,即完成将PDF文档中的条形码插入到标签中的操作。 点击了解此功能在跨境电商中的使用示例:如何将商品条形码合并到欧盟GPSR合规标签中 。
如何确认条形码的码制?
按照上面的说明内容,识别出来2列内容,第1列是条形码的文本内容,第2列是对应的码制,因此,从第2列的内容即可以获得条形码的码制。 如果仍难以确认条形码的码制,可以将条形码的图片反馈给多零,多零为您分析出对应的码制。
注意事项
-
如果您使用的浏览器版本太旧,可能无法使用PDF文档导入功能,多零建议,使用主流新版本的浏览器,例如:Chrome、Edge、Safari、Firefox。
-
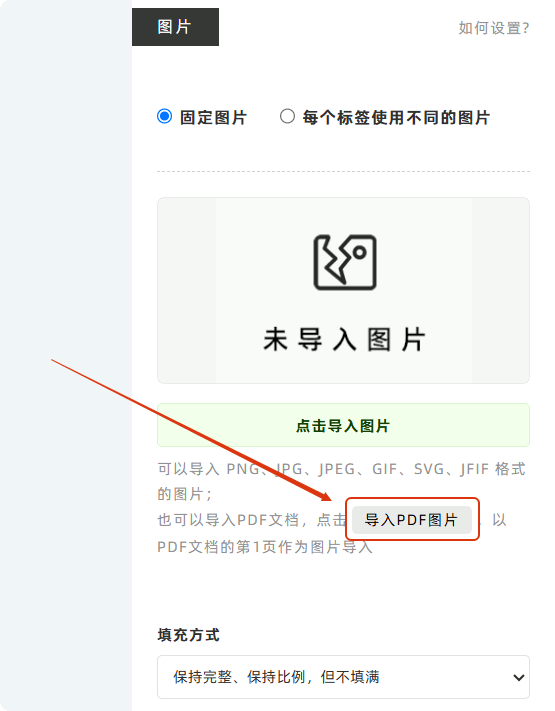
如果不需要批量导入PDF条形码,只需要导入PDF第1页的图片,那么使用标签生成器的图片组件即可,此功能可以导入1张PDF图片。图片组件设置中点击【导入PDF图片】,即可将PDF文档中的第1页作为图片导入到标签中。
由于持续版本迭代,本文涉及的功能内容和界面截图可能没有及时更新,文章内容可能会有差异,如需最准确的信息,请查阅最新版本的功能。